Detect and track objects
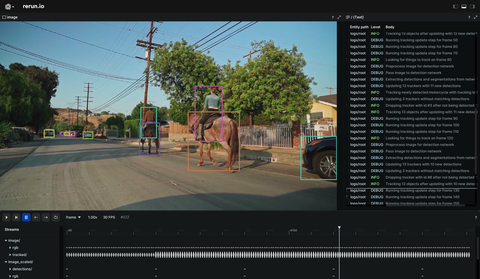
Visualize object detection and segmentation using the Huggingface's Transformers and CSRT from OpenCV.
Used Rerun types
Image, SegmentationImage, AnnotationContext, Boxes2D, TextLog
Background
In this example, CSRT (Channel and Spatial Reliability Tracker), a tracking API introduced in OpenCV, is employed for object detection and tracking across frames. Additionally, the example showcases basic object detection and segmentation on a video using the Huggingface transformers library.
Logging and visualizing with Rerun
The visualizations in this example were created with the following Rerun code.
Timelines
For each processed video frame, all data sent to Rerun is associated with the timelines frame_idx.
rr.set_time_sequence("frame", frame_idx)
Video
The input video is logged as a sequence of Image to the image entity.
rr.log( "image", rr.Image(rgb).compress(jpeg_quality=85) )
Since the detection and segmentation model operates on smaller images the resized images are logged to the separate segmentation/rgb_scaled entity.
This allows us to subsequently visualize the segmentation mask on top of the video.
rr.log( "segmentation/rgb_scaled", rr.Image(rgb_scaled).compress(jpeg_quality=85) )
Segmentations
The segmentation results is logged through a combination of two archetypes.
The segmentation image itself is logged as an
SegmentationImage and
contains the id for each pixel. It is logged to the segmentation entity.
rr.log( "segmentation", rr.SegmentationImage(mask) )
The color and label for each class is determined by the
AnnotationContext which is
logged to the root entity using rr.log("/", …, timeless=True) as it should apply to the whole sequence and all
entities that have a class id.
class_descriptions = [ rr.AnnotationInfo(id=cat["id"], color=cat["color"], label=cat["name"]) for cat in coco_categories ] rr.log( "/", rr.AnnotationContext(class_descriptions), timeless=True )
Detections
The detections and tracked bounding boxes are visualized by logging the Boxes2D to Rerun.
Detections
rr.log( "segmentation/detections/things", rr.Boxes2D( array=thing_boxes, array_format=rr.Box2DFormat.XYXY, class_ids=thing_class_ids, ), )
rr.log( f"image/tracked/{self.tracking_id}", rr.Boxes2D( array=self.tracked.bbox_xywh, array_format=rr.Box2DFormat.XYWH, class_ids=self.tracked.class_id, ), )
Tracked bounding boxes
rr.log( "segmentation/detections/background", rr.Boxes2D( array=background_boxes, array_format=rr.Box2DFormat.XYXY, class_ids=background_class_ids, ), )
The color and label of the bounding boxes is determined by their class id, relying on the same
AnnotationContext as the
segmentation images. This ensures that a bounding box and a segmentation image with the same class id will also have the
same color.
Note that it is also possible to log multiple annotation contexts should different colors and / or labels be desired. The annotation context is resolved by seeking up the entity hierarchy.
Text log
Rerun integrates with the Python logging module.
Through the TextLog text at different importance level can be logged. After an initial setup that is described on the
TextLog, statements
such as logging.info("…"), logging.debug("…"), etc. will show up in the Rerun viewer.
def setup_logging() -> None: logger = logging.getLogger() rerun_handler = rr.LoggingHandler("logs") rerun_handler.setLevel(-1) logger.addHandler(rerun_handler) def main() -> None: # … existing code … setup_logging() # setup logging track_objects(video_path, max_frame_count=args.max_frame) # start tracking
In the viewer you can adjust the filter level and look at the messages time-synchronized with respect to other logged data.
Run the code
To run this example, make sure you have the Rerun repository checked out and the latest SDK installed:
# Setup pip install --upgrade rerun-sdk # install the latest Rerun SDK git clone git@github.com:rerun-io/rerun.git # Clone the repository cd rerun git checkout latest # Check out the commit matching the latest SDK release
Install the necessary libraries specified in the requirements file:
pip install -e examples/python/detect_and_track_objects
To experiment with the provided example, simply execute the main Python script:
python -m detect_and_track_objects # run the example
If you wish to customize it for various videos, adjust the maximum frames, explore additional features, or save it use the CLI with the --help option for guidance:
python -m detect_and_track_objects --help